/// Method to try and mark a result as invalid. /// /// When the outer analysis manager detects a change in some underlying /// unit of the IR, it will call this method on all of the results cached. /// /// \p PA is a set of preserved analyses which can be used to avoid /// invalidation because the pass which changed the underlying IR took care /// to update or preserve the analysis result in some way. /// /// \p Inv is typically a \c AnalysisManager::Invalidator object that can be /// used by a particular analysis result to discover if other analyses /// results are also invalidated in the event that this result depends on /// them. See the documentation in the \c AnalysisManager for more details. /// /// \returns true if the result is indeed invalid (the default). virtualboolinvalidate(IRUnitT &IR, const PreservedAnalysesT &PA, InvalidatorT &Inv)= 0; };
AnalysisResultModel
1 2 3 4 5 6 7 8 9 10 11
/// Wrapper to model the analysis result concept. /// /// By default, this will implement the invalidate method with a trivial /// implementation so that the actual analysis result doesn't need to provide /// an invalidation handler. It is only selected when the invalidation handler /// is not part of the ResultT's interface. template <typename IRUnitT, typename PassT, typename ResultT, typename PreservedAnalysesT, typename InvalidatorT, bool HasInvalidateHandler = ResultHasInvalidateMethod<IRUnitT, ResultT>::Value> struct AnalysisResultModel;
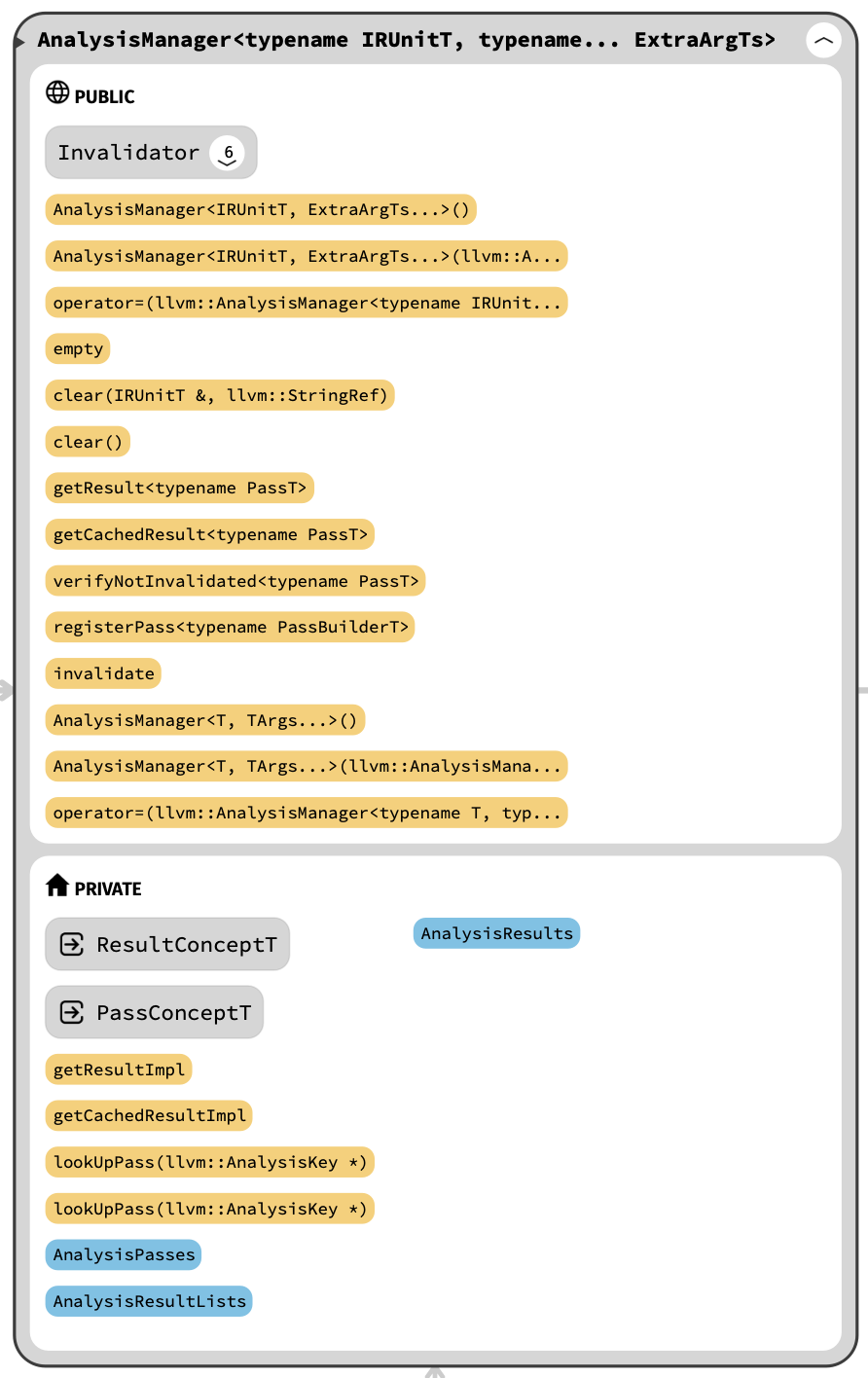
/// A container for analyses that lazily runs them and caches their /// results. /// /// This class can manage analyses for any IR unit where the address of the IR /// unit sufficies as its identity. template <typename IRUnitT, typename... ExtraArgTs> classAnalysisManager { ... }
// If we don't have a cached result for this function, look up the pass and // run it to produce a result, which we then add to the cache. if (Inserted) { auto &P = this->lookUpPass(ID);
PassInstrumentation PI; if (ID != PassInstrumentationAnalysis::ID()) { PI = getResult<PassInstrumentationAnalysis>(IR, ExtraArgs...); PI.runBeforeAnalysis(P, IR); }
// P.run may have inserted elements into AnalysisResults and invalidated // RI. RI = AnalysisResults.find({ID, &IR}); assert(RI != AnalysisResults.end() && "we just inserted it!");
RI->second = std::prev(ResultList.end()); }
return *RI->second->second; }
getResult
1 2 3 4 5 6 7 8 9 10 11 12 13
template <typename PassT> typename PassT::Result &getResult(IRUnitT &IR, ExtraArgTs... ExtraArgs){ assert(AnalysisPasses.count(PassT::ID()) && "This analysis pass was not registered prior to being queried"); ResultConceptT &ResultConcept = getResultImpl(PassT::ID(), IR, ExtraArgs...);
using ResultModelT = detail::AnalysisResultModel<IRUnitT, PassT, typename PassT::Result, PreservedAnalyses, Invalidator>;
/// Map type from a pair of analysis ID and IRUnitT pointer to an /// iterator into a particular result list (which is where the actual analysis /// result is stored). using AnalysisResultMapT = DenseMap<std::pair<AnalysisKey *, IRUnitT *>, typename AnalysisResultListT::iterator>;
key → std::make_pair(ID, &IR)
value → typename AnalysisResultListT::iterator()
也就是说通过一对(AnalysisKey *, IRUnitT *)来判断result是否存在
已经存在则直接返回值,不存在则表示没有cache,之后开始跑Pass。
1 2 3 4 5 6 7 8 9 10
PassInstrumentation PI; if (ID != PassInstrumentationAnalysis::ID()) { PI = getResult<PassInstrumentationAnalysis>(IR, ExtraArgs...); PI.runBeforeAnalysis(P, IR); }
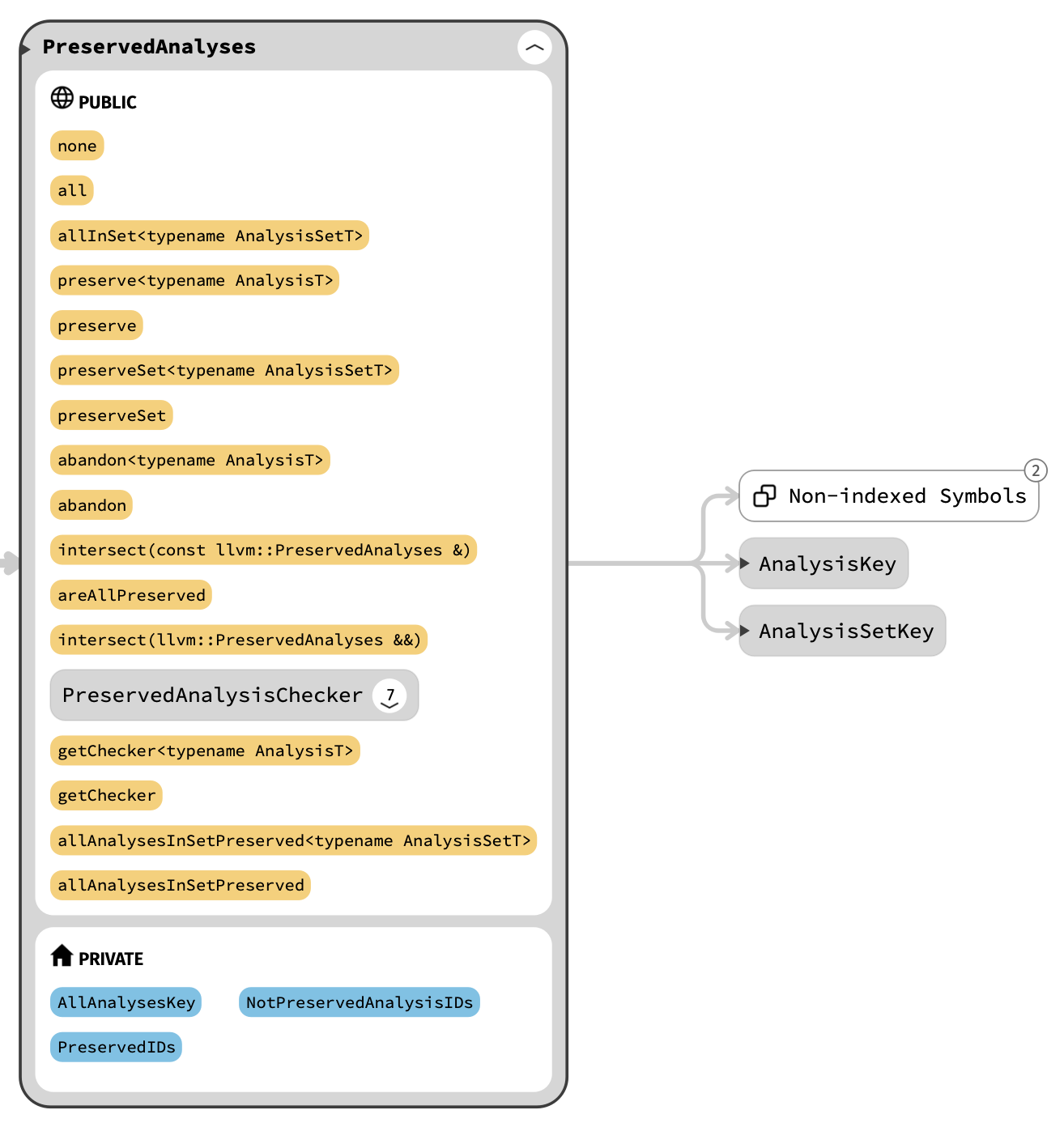
classPreservedAnalyses { private: /// A special key used to indicate all analyses. static AnalysisSetKey AllAnalysesKey;
/// The IDs of analyses and analysis sets that are preserved. SmallPtrSet<void *, 2> PreservedIDs;
/// The IDs of explicitly not-preserved analyses. /// /// If an analysis in this set is covered by a set in `PreservedIDs`, we /// consider it not-preserved. That is, `NotPreservedAnalysisIDs` always /// "wins" over analysis sets in `PreservedIDs`. /// /// Also, a given ID should never occur both here and in `PreservedIDs`. SmallPtrSet<AnalysisKey *, 2> NotPreservedAnalysisIDs; }
/// This templated class represents "all analyses that operate over \<a /// particular IR unit\>" (e.g. a Function or a Module) in instances of /// PreservedAnalysis. /// /// This lets a transformation say e.g. "I preserved all function analyses". /// /// Note that you must provide an explicit instantiation declaration and /// definition for this template in order to get the correct behavior on /// Windows. Otherwise, the address of SetKey will not be stable. template <typename IRUnitT> classAllAnalysesOn { public: static AnalysisSetKey *ID(){ return &SetKey; }
classPreservedAnalyses { public: /// Convenience factory function for the empty preserved set. static PreservedAnalyses none(){ returnPreservedAnalyses(); }
/// Construct a special preserved set that preserves all passes. static PreservedAnalyses all(){ PreservedAnalyses PA; PA.PreservedIDs.insert(&AllAnalysesKey); return PA; } /// Construct a preserved analyses object with a single preserved set. template <typename AnalysisSetT> static PreservedAnalyses allInSet(){ PreservedAnalyses PA; PA.preserveSet<AnalysisSetT>(); return PA; }
/// Mark an analysis as preserved. template <typename AnalysisT> voidpreserve(){ preserve(AnalysisT::ID()); }
/// Given an analysis's ID, mark the analysis as preserved, adding it /// to the set. voidpreserve(AnalysisKey *ID){ // Clear this ID from the explicit not-preserved set if present. NotPreservedAnalysisIDs.erase(ID);
// If we're not already preserving all analyses (other than those in // NotPreservedAnalysisIDs). if (!areAllPreserved()) PreservedIDs.insert(ID); }
/// Mark an analysis set as preserved. template <typename AnalysisSetT> voidpreserveSet(){ preserveSet(AnalysisSetT::ID()); }
/// Mark an analysis set as preserved using its ID. voidpreserveSet(AnalysisSetKey *ID){ // If we're not already in the saturated 'all' state, add this set. if (!areAllPreserved()) PreservedIDs.insert(ID); } ... }
/// Mark an analysis as abandoned. /// /// An abandoned analysis is not preserved, even if it is nominally covered /// by some other set or was previously explicitly marked as preserved. /// /// Note that you can only abandon a specific analysis, not a *set* of /// analyses. template <typename AnalysisT> voidabandon(){ abandon(AnalysisT::ID()); }
/// Mark an analysis as abandoned using its ID. /// /// An abandoned analysis is not preserved, even if it is nominally covered /// by some other set or was previously explicitly marked as preserved. /// /// Note that you can only abandon a specific analysis, not a *set* of /// analyses. voidabandon(AnalysisKey *ID){ PreservedIDs.erase(ID); NotPreservedAnalysisIDs.insert(ID); }
/// Intersect this set with another in place. /// /// This is a mutating operation on this preserved set, removing all /// preserved passes which are not also preserved in the argument. voidintersect(const PreservedAnalyses &Arg){ if (Arg.areAllPreserved()) return; if (areAllPreserved()) { *this = Arg; return; } // The intersection requires the *union* of the explicitly not-preserved // IDs and the *intersection* of the preserved IDs. for (auto ID : Arg.NotPreservedAnalysisIDs) { PreservedIDs.erase(ID); NotPreservedAnalysisIDs.insert(ID); } for (auto ID : PreservedIDs) if (!Arg.PreservedIDs.count(ID)) PreservedIDs.erase(ID); }
/// Intersect this set with a temporary other set in place. /// /// This is a mutating operation on this preserved set, removing all /// preserved passes which are not also preserved in the argument. voidintersect(PreservedAnalyses &&Arg){ if (Arg.areAllPreserved()) return; if (areAllPreserved()) { *this = std::move(Arg); return; } // The intersection requires the *union* of the explicitly not-preserved // IDs and the *intersection* of the preserved IDs. for (auto ID : Arg.NotPreservedAnalysisIDs) { PreservedIDs.erase(ID); NotPreservedAnalysisIDs.insert(ID); } for (auto ID : PreservedIDs) if (!Arg.PreservedIDs.count(ID)) PreservedIDs.erase(ID); }
invalidate
声明
1 2 3 4 5
/// Invalidate cached analyses for an IR unit. /// /// Walk through all of the analyses pertaining to this unit of IR and /// invalidate them, unless they are preserved by the PreservedAnalyses set. voidinvalidate(IRUnitT &IR, const PreservedAnalyses &PA);
template <typename IRUnitT, typename... ExtraArgTs> inlinevoid AnalysisManager<IRUnitT, ExtraArgTs...>::invalidate( IRUnitT &IR, const PreservedAnalyses &PA) { // We're done if all analyses on this IR unit are preserved. if (PA.allAnalysesInSetPreserved<AllAnalysesOn<IRUnitT>>()) return;
// Track whether each analysis's result is invalidated in // IsResultInvalidated. SmallDenseMap<AnalysisKey *, bool, 8> IsResultInvalidated; Invalidator Inv(IsResultInvalidated, AnalysisResults); AnalysisResultListT &ResultsList = AnalysisResultLists[&IR]; for (auto &AnalysisResultPair : ResultsList) { // This is basically the same thing as Invalidator::invalidate, but we // can't call it here because we're operating on the type-erased result. // Moreover if we instead called invalidate() directly, it would do an // unnecessary look up in ResultsList. AnalysisKey *ID = AnalysisResultPair.first; auto &Result = *AnalysisResultPair.second;
auto IMapI = IsResultInvalidated.find(ID); if (IMapI != IsResultInvalidated.end()) // This result was already handled via the Invalidator. continue;
// Try to invalidate the result, giving it the Invalidator so it can // recursively query for any dependencies it has and record the result. // Note that we cannot reuse 'IMapI' here or pre-insert the ID, as // Result.invalidate may insert things into the map, invalidating our // iterator. bool Inserted = IsResultInvalidated.insert({ID, Result.invalidate(IR, PA, Inv)}).second; (void)Inserted; assert(Inserted && "Should never have already inserted this ID, likely " "indicates a cycle!"); }
// Now erase the results that were marked above as invalidated. if (!IsResultInvalidated.empty()) { for (auto I = ResultsList.begin(), E = ResultsList.end(); I != E;) { AnalysisKey *ID = I->first; if (!IsResultInvalidated.lookup(ID)) { ++I; continue; }
if (auto *PI = getCachedResult<PassInstrumentationAnalysis>(IR)) PI->runAnalysisInvalidated(this->lookUpPass(ID), IR);
I = ResultsList.erase(I); AnalysisResults.erase({ID, &IR}); } }
if (ResultsList.empty()) AnalysisResultLists.erase(&IR); }
IsAllPreserved
首先是判断是否这个set是被preserved的
1 2 3
// We're done if all analyses on this IR unit are preserved. if (PA.allAnalysesInSetPreserved<AllAnalysesOn<IRUnitT>>()) return;
/// Directly test whether a set of analyses is preserved. /// /// This is only true when no analyses have been explicitly abandoned. boolallAnalysesInSetPreserved(AnalysisSetKey *SetID)const{ return NotPreservedAnalysisIDs.empty() && (PreservedIDs.count(&AllAnalysesKey) || PreservedIDs.count(SetID)); }
// Now erase the results that were marked above as invalidated. if (!IsResultInvalidated.empty()) { for (auto I = ResultsList.begin(), E = ResultsList.end(); I != E;) { AnalysisKey *ID = I->first; if (!IsResultInvalidated.lookup(ID)) { ++I; continue; }
if (auto *PI = getCachedResult<PassInstrumentationAnalysis>(IR)) PI->runAnalysisInvalidated(this->lookUpPass(ID), IR);
I = ResultsList.erase(I); AnalysisResults.erase({ID, &IR}); } }
if (ResultsList.empty()) AnalysisResultLists.erase(&IR);
By default, this will implement the invalidate method with a trivial implementation so that the actual analysis result doesn’t need to provide an invalidation handler. It is only selected when the invalidation handler is not part of the ResultT’s interface.
classPreservedAnalyses { public: /// Build a checker for this `PreservedAnalyses` and the specified analysis /// type. /// /// You can use the returned object to query whether an analysis was /// preserved. See the example in the comment on `PreservedAnalysis`. template <typename AnalysisT> PreservedAnalysisChecker getChecker()const{ returnPreservedAnalysisChecker(*this, AnalysisT::ID()); }
/// Build a checker for this `PreservedAnalyses` and the specified analysis /// ID. /// /// You can use the returned object to query whether an analysis was /// preserved. See the example in the comment on `PreservedAnalysis`. PreservedAnalysisChecker getChecker(AnalysisKey *ID)const{ returnPreservedAnalysisChecker(*this, ID); } }
/// A PreservedAnalysisChecker is tied to a particular Analysis because /// `preserved()` and `preservedSet()` both return false if the Analysis /// was abandoned. PreservedAnalysisChecker(const PreservedAnalyses &PA, AnalysisKey *ID) : PA(PA), ID(ID), IsAbandoned(PA.NotPreservedAnalysisIDs.count(ID)) {}
/// Returns true if the checker's analysis was not abandoned and either /// - the analysis is explicitly preserved or /// - all analyses are preserved. boolpreserved(){ return !IsAbandoned && (PA.PreservedIDs.count(&AllAnalysesKey) || PA.PreservedIDs.count(ID)); }
/// Returns true if the checker's analysis was not abandoned and either /// - \p AnalysisSetT is explicitly preserved or /// - all analyses are preserved. template <typename AnalysisSetT> boolpreservedSet(){ AnalysisSetKey *SetID = AnalysisSetT::ID(); return !IsAbandoned && (PA.PreservedIDs.count(&AllAnalysesKey) || PA.PreservedIDs.count(SetID)); } }
/// Analysis pass which computes a \c DominatorTree. classDominatorTreeAnalysis :public AnalysisInfoMixin<DominatorTreeAnalysis> { ... /// Provide the result typedef for this analysis pass. using Result = DominatorTree; ... }
boolDominatorTree::invalidate(Function &F, const PreservedAnalyses &PA, FunctionAnalysisManager::Invalidator &){ // Check whether the analysis, all analyses on functions, or the function's // CFG have been preserved. auto PAC = PA.getChecker<DominatorTreeAnalysis>(); return !(PAC.preserved() || PAC.preservedSet<AllAnalysesOn<Function>>() || PAC.preservedSet<CFGAnalyses>()); }
1 2 3 4 5 6 7 8 9 10 11 12 13
classCallGraphAnalysis :public AnalysisInfoMixin<CallGraphAnalysis> { ... using Result = CallGraph; }
boolCallGraph::invalidate(Module &, const PreservedAnalyses &PA, ModuleAnalysisManager::Invalidator &){ // Check whether the analysis, all analyses on functions, or the function's // CFG have been preserved. auto PAC = PA.getChecker<CallGraphAnalysis>(); return !(PAC.preserved() || PAC.preservedSet<AllAnalysesOn<Module>>() || PAC.preservedSet<CFGAnalyses>()); }