if (ctx.__dso_handle) { ctx.__dso_handle->set_output_section(sections[0]); ctx.__dso_handle->value = sections[0]->shdr.sh_addr; }
// __rel_iplt_start and __rel_iplt_end. These symbols need to be // defined in a statically-linked non-relocatable executable because // such executable lacks the .dynamic section and thus there's no way // to find ifunc relocations other than these symbols. // // We don't want to set values to these symbols if we are creating a // static PIE due to a glibc bug. Static PIE has a dynamic section. // If we set values to these symbols in a static PIE, glibc attempts // to run ifunc initializers twice, with the second attempt with wrong // function addresses, causing a segmentation fault. if (ctx.reldyn && ctx.arg.is_static && !ctx.arg.pie) { stop(ctx.__rel_iplt_start, ctx.reldyn); stop(ctx.__rel_iplt_end, ctx.reldyn);
// __{init,fini}_array_{start,end} for (Chunk<E> *chunk : sections) { switch (chunk->shdr.sh_type) { case SHT_INIT_ARRAY: start(ctx.__init_array_start, chunk); stop(ctx.__init_array_end, chunk); break; case SHT_PREINIT_ARRAY: start(ctx.__preinit_array_start, chunk); stop(ctx.__preinit_array_end, chunk); break; case SHT_FINI_ARRAY: start(ctx.__fini_array_start, chunk); stop(ctx.__fini_array_end, chunk); break; } }
// _end, _etext, _edata and the like for (Chunk<E> *chunk : sections) { if (chunk->shdr.sh_flags & SHF_ALLOC) { stop(ctx._end, chunk); stop(ctx.end, chunk); }
if (chunk->shdr.sh_flags & SHF_EXECINSTR) { stop(ctx._etext, chunk); stop(ctx.etext, chunk); }
// _GLOBAL_OFFSET_TABLE_. I don't know why, but for the sake of // compatibility with existing code, it must be set to the beginning of // .got.plt instead of .got only on i386 and x86-64. ifconstexpr(is_x86<E>) start(ctx._GLOBAL_OFFSET_TABLE_, ctx.gotplt); else start(ctx._GLOBAL_OFFSET_TABLE_, ctx.got);
// _PROCEDURE_LINKAGE_TABLE_. We need this on SPARC. start(ctx._PROCEDURE_LINKAGE_TABLE_, ctx.plt);
// _TLS_MODULE_BASE_. This symbol is used to obtain the address of // the TLS block in the TLSDESC model. I believe GCC and Clang don't // create a reference to it, but Intel compiler seems to be using // this symbol. if (ctx._TLS_MODULE_BASE_) { ctx._TLS_MODULE_BASE_->set_output_section(sections[0]); ctx._TLS_MODULE_BASE_->value = ctx.tls_begin; }
// --section-order symbols for (SectionOrder &ord : ctx.arg.section_order) if (ord.type == SectionOrder::SYMBOL) get_symbol(ctx, ord.name)->set_output_section(sections[0]); }
compress_debug_sections
1 2 3 4
// If --compress-debug-sections is given, compress .debug_* sections // using zlib. if (ctx.arg.compress_debug_sections != COMPRESS_NONE) filesize = compress_debug_sections(ctx);
// Copy chunks to an output file template <typename E> voidcopy_chunks(Context<E> &ctx){ Timer t(ctx, "copy_chunks");
auto copy = [&](Chunk<E> &chunk) { std::string name = chunk.name.empty() ? "(header)" : std::string(chunk.name); Timer t2(ctx, name, &t); chunk.copy_buf(ctx); };
// For --relocatable and --emit-relocs, we want to copy non-relocation // sections first. This is because REL-type relocation sections (as // opposed to RELA-type) stores relocation addends to target sections. tbb::parallel_for_each(ctx.chunks, [&](Chunk<E> *chunk) { if (chunk->shdr.sh_type != (is_rela<E> ? SHT_RELA : SHT_REL)) copy(*chunk); });
template <typename E> void OutputSection<E>::write_to(Context<E> &ctx, u8 *buf) { auto clear = [&](u8 *loc, i64 size) { // As a special case, .init and .fini are filled with NOPs because the // runtime executes the sections as if they were a single function. // .init and .fini are superceded by .init_array and .fini_array and // being actively used only on s390x though. if (is_s390x<E> && (this->name == ".init" || this->name == ".fini")) { for (i64 i = 0; i < size; i += 2) *(ub16 *)(loc + i) = 0x0700; // nop } else { memset(loc, 0, size); } };
auto check = [&](i64 val, i64 lo, i64 hi) { if (val < lo || hi <= val) Error(ctx) << *this << ": relocation " << rel << " against " << sym << " out of range: " << val << " is not in [" << lo << ", " << hi << ")"; };
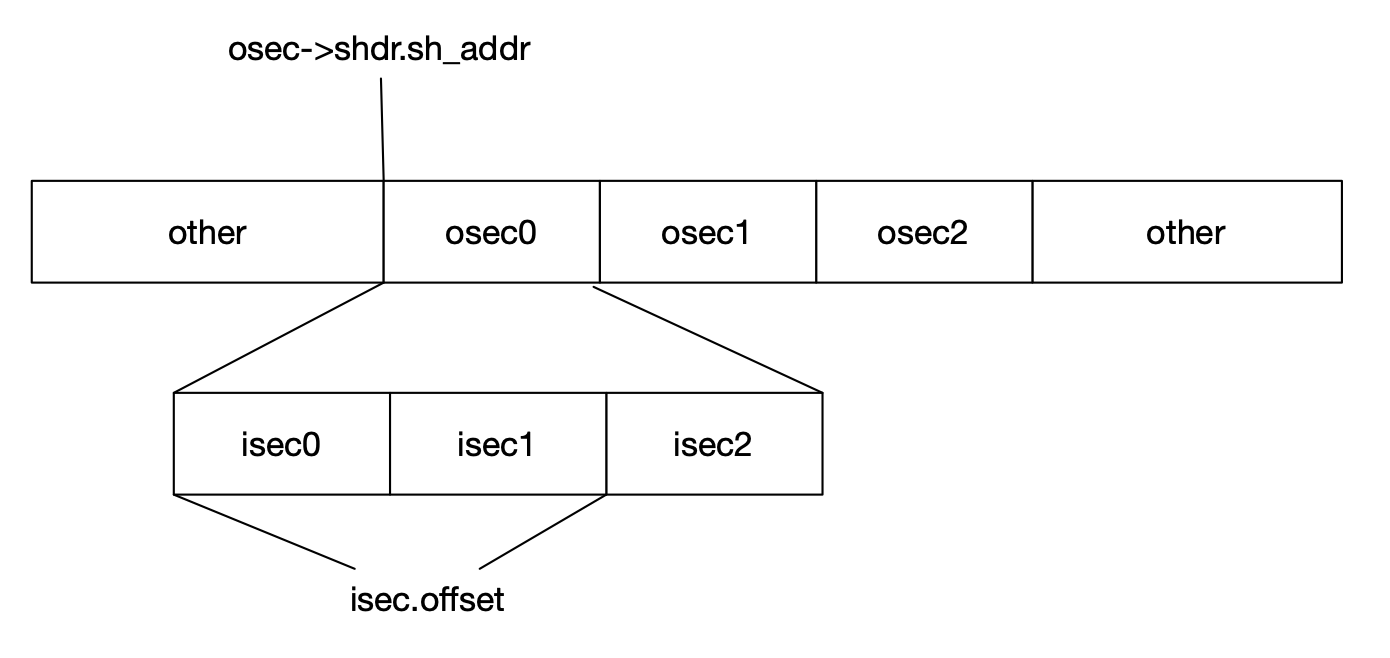
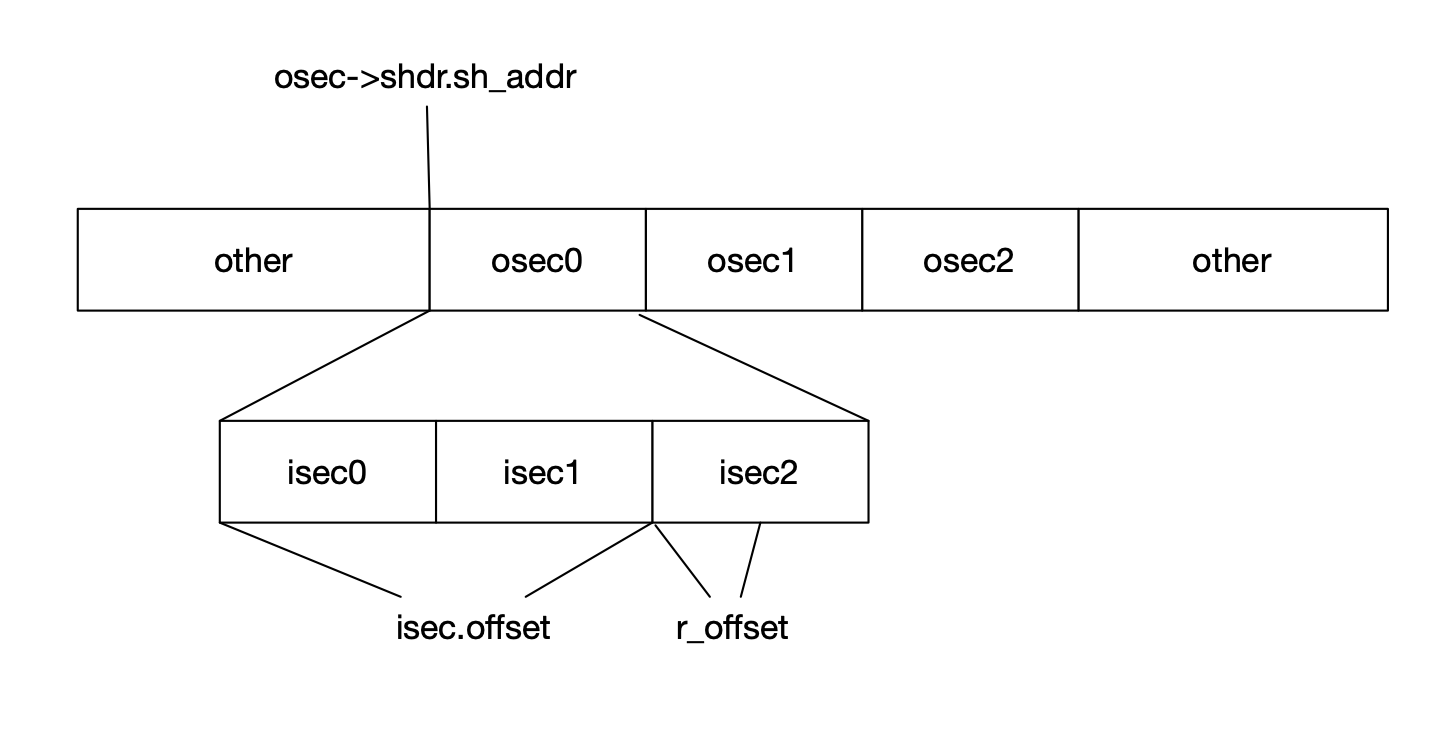
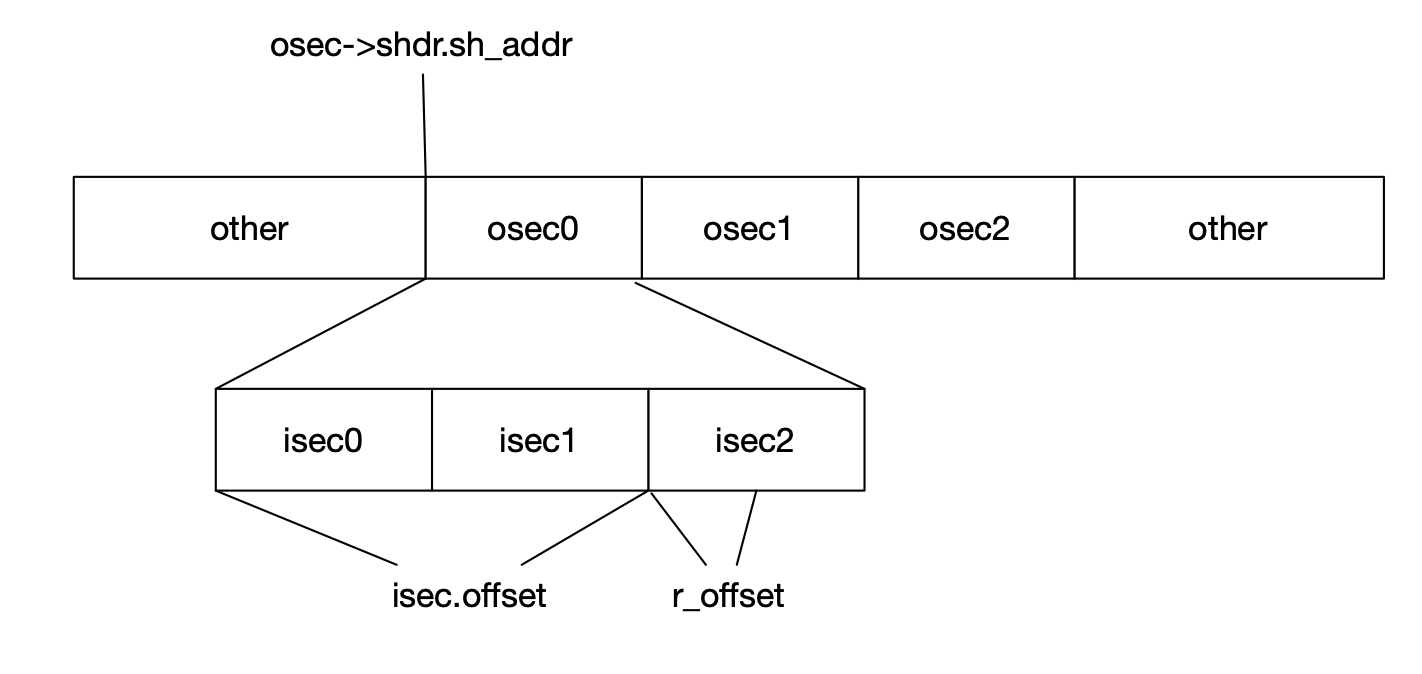
#define S sym.get_addr(ctx) #define A rel.r_addend #define P (get_addr() + r_offset) #define G (sym.get_got_idx(ctx) * sizeof(Word<E>)) #define GOT ctx.got->shdr.sh_addr
switch (rel.r_type) { case R_RISCV_32: ifconstexpr(E::is_64) *(U32<E> *)loc = S + A; else apply_dyn_absrel(ctx, sym, rel, loc, S, A, P, dynrel); break; case R_RISCV_64: assert(E::is_64); apply_dyn_absrel(ctx, sym, rel, loc, S, A, P, dynrel); break; case R_RISCV_BRANCH: { i64 val = S + A - P; check(val, -(1 << 12), 1 << 12); write_btype(loc, val); break; } case R_RISCV_JAL: { i64 val = S + A - P; check(val, -(1 << 20), 1 << 20); write_jtype(loc, val); break; } case R_RISCV_CALL: case R_RISCV_CALL_PLT: { u32 rd = get_rd(*(ul32 *)(contents.data() + rel.r_offset + 4));
if (removed_bytes == 4) { // auipc + jalr -> jal *(ul32 *)loc = (rd << 7) | 0b1101111; write_jtype(loc, S + A - P); } elseif (removed_bytes == 6 && rd == 0) { // auipc + jalr -> c.j *(ul16 *)loc = 0b101'00000000000'01; write_cjtype(loc, S + A - P); } elseif (removed_bytes == 6 && rd == 1) { // auipc + jalr -> c.jal assert(!E::is_64); *(ul16 *)loc = 0b001'00000000000'01; write_cjtype(loc, S + A - P); } else { assert(removed_bytes == 0); u64 val = sym.esym().is_undef_weak() ? 0 : S + A - P; check(val, -(1LL << 31), 1LL << 31); write_utype(loc, val); write_itype(loc + 4, val); } break; } case R_RISCV_GOT_HI20: *(ul32 *)loc = G + GOT + A - P; break; case R_RISCV_TLS_GOT_HI20: *(ul32 *)loc = sym.get_gottp_addr(ctx) + A - P; break; case R_RISCV_TLS_GD_HI20: *(ul32 *)loc = sym.get_tlsgd_addr(ctx) + A - P; break; case R_RISCV_PCREL_HI20: if (sym.esym().is_undef_weak()) { // Calling an undefined weak symbol does not make sense. // We make such call into an infinite loop. This should // help debugging of a faulty program. *(ul32 *)loc = 0; } else { *(ul32 *)loc = S + A - P; } break; case R_RISCV_HI20: { i64 val = S + A; if (removed_bytes == 0) { check(val, -(1LL << 31), 1LL << 31); write_utype(loc, val); } else { assert(removed_bytes == 4); assert(sign_extend(val, 11) == val); } break; } case R_RISCV_LO12_I: case R_RISCV_LO12_S: { i64 val = S + A; if (rel.r_type == R_RISCV_LO12_I) write_itype(loc, val); else write_stype(loc, val);
// Rewrite `lw t1, 0(t0)` with `lw t1, 0(x0)` if the address is // accessible relative to the zero register. If the upper 20 bits // are all zero, the corresponding LUI might have been removed. if (sign_extend(val, 11) == val) set_rs1(loc, 0); break; } case R_RISCV_TPREL_HI20: assert(removed_bytes == 0 || removed_bytes == 4); if (removed_bytes == 0) write_utype(loc, S + A - ctx.tp_addr); break; case R_RISCV_TPREL_ADD: break; case R_RISCV_TPREL_LO12_I: case R_RISCV_TPREL_LO12_S: { i64 val = S + A - ctx.tp_addr; if (rel.r_type == R_RISCV_TPREL_LO12_I) write_itype(loc, val); else write_stype(loc, val);
// Rewrite `lw t1, 0(t0)` with `lw t1, 0(tp)` if the address is // directly accessible using tp. tp is x4. if (sign_extend(val, 11) == val) set_rs1(loc, 4); break; } case R_RISCV_ADD8: loc += S + A; break; case R_RISCV_ADD16: *(U16<E> *)loc += S + A; break; case R_RISCV_ADD32: *(U32<E> *)loc += S + A; break; case R_RISCV_ADD64: *(U64<E> *)loc += S + A; break; case R_RISCV_SUB8: loc -= S + A; break; case R_RISCV_SUB16: *(U16<E> *)loc -= S + A; break; case R_RISCV_SUB32: *(U32<E> *)loc -= S + A; break; case R_RISCV_SUB64: *(U64<E> *)loc -= S + A; break; case R_RISCV_ALIGN: { // A R_RISCV_ALIGN is followed by a NOP sequence. We need to remove // zero or more bytes so that the instruction after R_RISCV_ALIGN is // aligned to a given alignment boundary. // // We need to guarantee that the NOP sequence is valid after byte // removal (e.g. we can't remove the first 2 bytes of a 4-byte NOP). // For the sake of simplicity, we always rewrite the entire NOP sequence. i64 padding_bytes = rel.r_addend - removed_bytes; assert((padding_bytes & 1) == 0);
i64 i = 0; for (; i <= padding_bytes - 4; i += 4) *(ul32 *)(loc + i) = 0x0000'0013; // nop if (i < padding_bytes) *(ul16 *)(loc + i) = 0x0001; // c.nop break; } case R_RISCV_RVC_BRANCH: { i64 val = S + A - P; check(val, -(1 << 8), 1 << 8); write_cbtype(loc, val); break; } case R_RISCV_RVC_JUMP: { i64 val = S + A - P; check(val, -(1 << 11), 1 << 11); write_cjtype(loc, val); break; } case R_RISCV_SUB6: *loc = (*loc & 0b1100'0000) | ((*loc - (S + A)) & 0b0011'1111); break; case R_RISCV_SET6: *loc = (*loc & 0b1100'0000) | ((S + A) & 0b0011'1111); break; case R_RISCV_SET8: *loc = S + A; break; case R_RISCV_SET16: *(U16<E> *)loc = S + A; break; case R_RISCV_SET32: *(U32<E> *)loc = S + A; break; case R_RISCV_32_PCREL: *(U32<E> *)loc = S + A - P; break; case R_RISCV_PCREL_LO12_I: case R_RISCV_PCREL_LO12_S: // These relocations are handled in the next loop. break; default: unreachable(); }
#undef S #undef A #undef P #undef G #undef GOT }
// Handle PC-relative LO12 relocations. In the above loop, pcrel HI20 // relocations overwrote instructions with full 32-bit values to allow // their corresponding pcrel LO12 relocations to read their values. for (i64 i = 0; i < rels.size(); i++) { switch (rels[i].r_type) { case R_RISCV_PCREL_LO12_I: case R_RISCV_PCREL_LO12_S: { Symbol<E> &sym = *file.symbols[rels[i].r_sym]; assert(sym.get_input_section() == this);
u8 *loc = base + rels[i].r_offset - get_r_delta(i); u32 val = *(ul32 *)(base + sym.value);
// Restore the original instructions pcrel HI20 relocations overwrote. for (i64 i = 0; i < rels.size(); i++) { switch (rels[i].r_type) { case R_RISCV_GOT_HI20: case R_RISCV_PCREL_HI20: case R_RISCV_TLS_GOT_HI20: case R_RISCV_TLS_GD_HI20: { u8 *loc = base + rels[i].r_offset - get_r_delta(i); u32 val = *(ul32 *)loc; memcpy(loc, contents.data() + rels[i].r_offset, 4); write_utype(loc, val); } } } }
// Some part of .gdb_index couldn't be computed until other debug // sections are complete. We have complete debug sections now, so // write the rest of .gdb_index. if (ctx.gdb_index) ctx.gdb_index->write_address_areas(ctx);
for (Chunk<E> *chunk : ctx.chunks) { std::string_view name = chunk->name; if (name == ".debug_info") ctx.debug_info = chunk; if (name == ".debug_abbrev") ctx.debug_abbrev = chunk; if (name == ".debug_ranges") ctx.debug_ranges = chunk; if (name == ".debug_addr") ctx.debug_addr = chunk; if (name == ".debug_rnglists") ctx.debug_rnglists = chunk; }
assert(ctx.debug_info); assert(ctx.debug_abbrev);
structEntry { ul64 start; ul64 end; ul32 attr; };
// Read address ranges from debug sections and copy them to .gdb_index. tbb::parallel_for_each(ctx.objs, [&](ObjectFile<E> *file) { if (!file->debug_info) return;
// Fill trailing null entries with dummy values because gdb // crashes if there are entries with address 0. u64 filler; if (e == begin) filler = ctx.etext->get_addr(ctx) - 1; else filler = e[-1].start;
for (; e < begin + file->num_areas; e++) { e->start = filler; e->end = filler; e->attr = file->compunits_idx; } }); }
sort reldyn
1 2 3
// Dynamic linker works better with sorted .rela.dyn section, // so we sort them. ctx.reldyn->sort(ctx);
对rel段排序,这么做的原理如注释所描述
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
// This is the reason why we sort dynamic relocations. Quote from // https://www.airs.com/blog/archives/186: // // The dynamic linker in glibc uses a one element cache when processing // relocs: if a relocation refers to the same symbol as the previous // relocation, then the dynamic linker reuses the value rather than // looking up the symbol again. Thus the dynamic linker gets the best // results if the dynamic relocations are sorted so that all dynamic // relocations for a given dynamic symbol are adjacent. // // Other than that, the linker sorts together all relative relocations, // which don't have symbols. Two relative relocations, or two relocations // against the same symbol, are sorted by the address in the output // file. This tends to optimize paging and caching when there are two // references from the same page. // // We group IFUNC relocations at the end of .rel.dyn because we want to // apply all the other relocations before running user-supplied ifunc // resolver functions.
for (i64 i = 1; i < chunks.size(); i++) zero(chunks[i - 1], chunks[i]->shdr.sh_offset); zero(chunks.back(), ctx.output_file->filesize); }
buildid
1 2 3 4 5
// .note.gnu.build-id section contains a cryptographic hash of the // entire output file. Now that we wrote everything except build-id, // we can compute it. if (ctx.buildid) ctx.buildid->write_buildid(ctx);
switch (ctx.arg.build_id.kind) { case BuildId::HEX: write_vector(ctx.buf + this->shdr.sh_offset + HEADER_SIZE, ctx.arg.build_id.value); return; case BuildId::HASH: // Modern x86 processors have purpose-built instructions to accelerate // SHA256 computation, and SHA256 outperforms MD5 on such computers. // So, we always compute SHA256 and truncate it if smaller digest was // requested. compute_sha256(ctx, this->shdr.sh_offset + HEADER_SIZE); return; case BuildId::UUID: { std::array<u8, 16> uuid = get_uuid_v4(); memcpy(ctx.buf + this->shdr.sh_offset + HEADER_SIZE, uuid.data(), 16); return; } default: unreachable(); } }
close file
1 2
// Close the output file. This is the end of the linker's main job. ctx.output_file->close(ctx);