由于工作需要,最近这段时间调研了一大批指令预取的论文。
其中这篇论文 A Survey of Recent Prefetching Techniques for Processor Caches 介绍了关于预取技术的所有常见概念,从软件预取到硬件预取,从预取数据到预取指令。预取方案的核心是提前加载相关的指令/数据到缓存中。有的通过简单的取next n line的方式提升效果,有的方案是通过存储额外的表去记录内存访问的影响进而预测指令/数据流,等等。
工作需要的是通过软件层面插入指令预取去预取指令,因为我们之前出现了严重的i cache miss引发的性能问题,所以需要尽可能规避i cache miss的损失。但是看论文的现状是硬件预取的实现方式比较多,软件则是基本集中于循环中的数据预取,关于软件进行预取指令的,符合需求的只有如下一篇:
Architectural and Compiler Support for Effective Instruction Prefetching: A Cooperative Approach
论文分析
该文章中的实现是软硬件相结合,基于其硬件设计了一套预取的算法,而即便在软件侧预取指令,由于缓存的特殊性,实现也都离不开硬件的结构和指令设计两方面。
文中硬件
该论文中采取的是软硬件结合的机制,但是依然能适用于纯软件预取(也因此选择参考该方案)。其中硬件的部分主要是预取过滤机制,用于减少无用预取带来的cache污染问题,可以使用更激进的顺序预取。(我认为这是软件预取比较有效的原因)
另外预取指令比较特殊,有四类
- 针对地址预取(直接预取特定地址,16byte / 2Byte对齐的地址)
- 针对两个地址预取(两个地址是偏移量,地址计算方式为PC + 偏移量)
- 针对返回值预取(存在返回地址栈,直接去栈上获取,无需参数)
- 针对indirect-jump预取(存在间接跳转表)
算法设计原则
尽可能的减少cache miss(首要目的)
尽可能避免重复的prefetch(降低无意义开销)
预取和实际执行要保持一定距离,隐藏延迟(进一步提升性能)
问题分类
文中将指令访问造成的cache miss分为两类问题
Sequential Access:通过next n line,即提取预取N行即可。理想方案是激进的预取到序列结束,该行为以硬件为主。
The ideal solution would be to prefetch ahead aggressively (i.e., with a large N) but to stop upon reaching the end of the sequence.
Nonsequential Access:硬件的各种基于表的实现不适用于软件,因此该论选择了通过编译器自动插入相关预取指令来处理该情况。
算法实现
该论文的实现将整个算法分为了两部分
- 插入基本的预取指令
- 对预取指令进行优化合并
the key challenge in designing a better instruction prefetching scheme is to be able to launch prefetches earlier—i.e., to achieve a larger prefetching distance
插入预取指令
论文中插入预取指令算法分为了direct的预取和indirect的预取,两个算法整体结构一致,只有些许细节不同。indirect不会考虑硬件预取的情况,另外indirect不会考虑locality like的情况(两个块同时出现在I cache中)
代码实现
以下是论文中贴出的主要代码,后续以伪代码的形式简化整个逻辑



伪代码描述
1 | Schedule_InDirect_Prefetches(B,T,D,S)其中 B:当前BB,T:target bb,D:distance,S:bb set |
核心思想可以用一段话总结:遍历每一个基本块,将当前基本块作为跳转目标的T,在cfg图中向前广度优先搜索,直到找到前驱基本块B,满足条件B到T的距离刚好大于预取距离,将预取指令插入到前驱B中。
该算法确保了每个基本块都在执行之前被预取。
locality likely

Locality_Likely:用于判断两个块是否大概率同时在i cache中
- 获取两个BB的公共基本块
- 循环体小于有效I cache size的情况下为true
换个方式来解释,满足以下条件的话大概率同时在i cache中
- 两个基本块在相同循环中(common loop)
- 进入循环之前被预取过。根据论文描述该条件由调用者保证
- 迭代过程中两个基本块都保持在icache中(最大loop size < 有效I cache size)
其中有效I cache size,论文中取实际的1/8。如果超过了有效size,那么可能导致在内部部分预取的cache失效,因此也是需要预取,如果没超过,那数据可能还残留在i cache。
预取指令优化合并
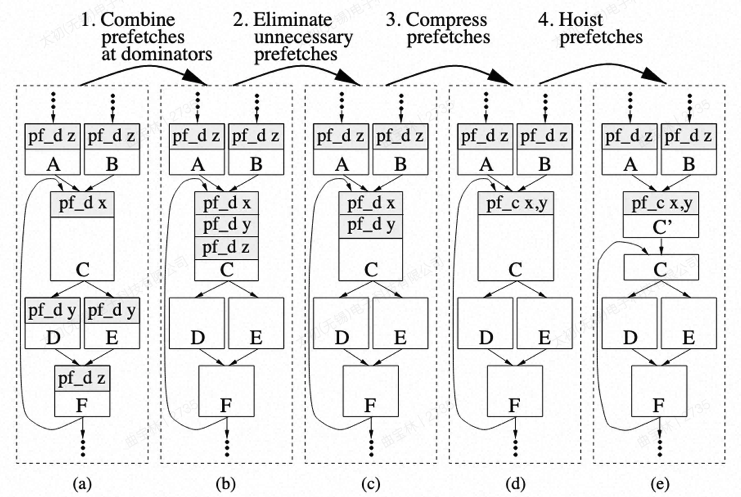
预取指令本身也要被解码,并且占用指令段大小。根据上述算法,会造成一个地址被多个基本块预取,因此需要通过优化合并多个预取指令。其中实现过程分为四步
- 将预取指令向上移动到最近的dominator中。(支配块到预取目标之间的指令量超过有效缓存大小,则该预取不会提升,本质是判断预取距离是否过大)
- 消除不必要预取指令,对自身的预取以及重复的预取
- 压缩预取指令(这是针对论文中提到的特殊指令,能够预取两个地址)
- 将预取指令从循环中外提
- 本文标题:软件指令预取论文调研
- 本文作者:Homura
- 创建时间:2025-08-15 15:19:10
- 本文链接:https://homura.live/2025/08/15/CS/inst-prefetch/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!