An archive can either be thin or it can be normal. It cannot be both at the same time. Once an archive is created its format cannot be changed without first deleting it and then creating a new archive in its place.
template <typename E> ObjectFile<E> *read_lto_object(Context<E> &ctx, MappedFile<Context<E>> *mf){ // V0 API's claim_file is not thread-safe. static std::mutex mu; std::unique_lock lock(mu, std::defer_lock); if (!is_gcc_linker_api_v1) lock.lock();
if (ctx.arg.plugin.empty()) Fatal(ctx) << mf->name << ": don't know how to handle this LTO object file " << "because no -plugin option was given. Please make sure you " << "added -flto not only for creating object files but also for " << "creating the final executable.";
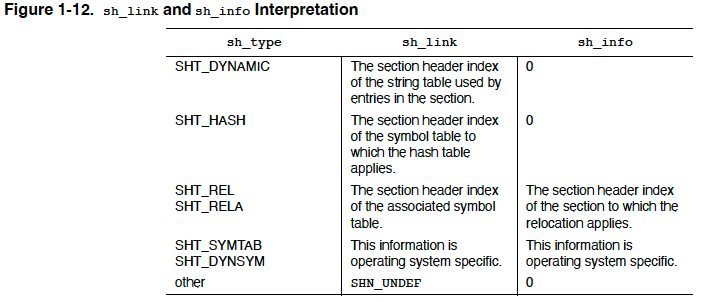
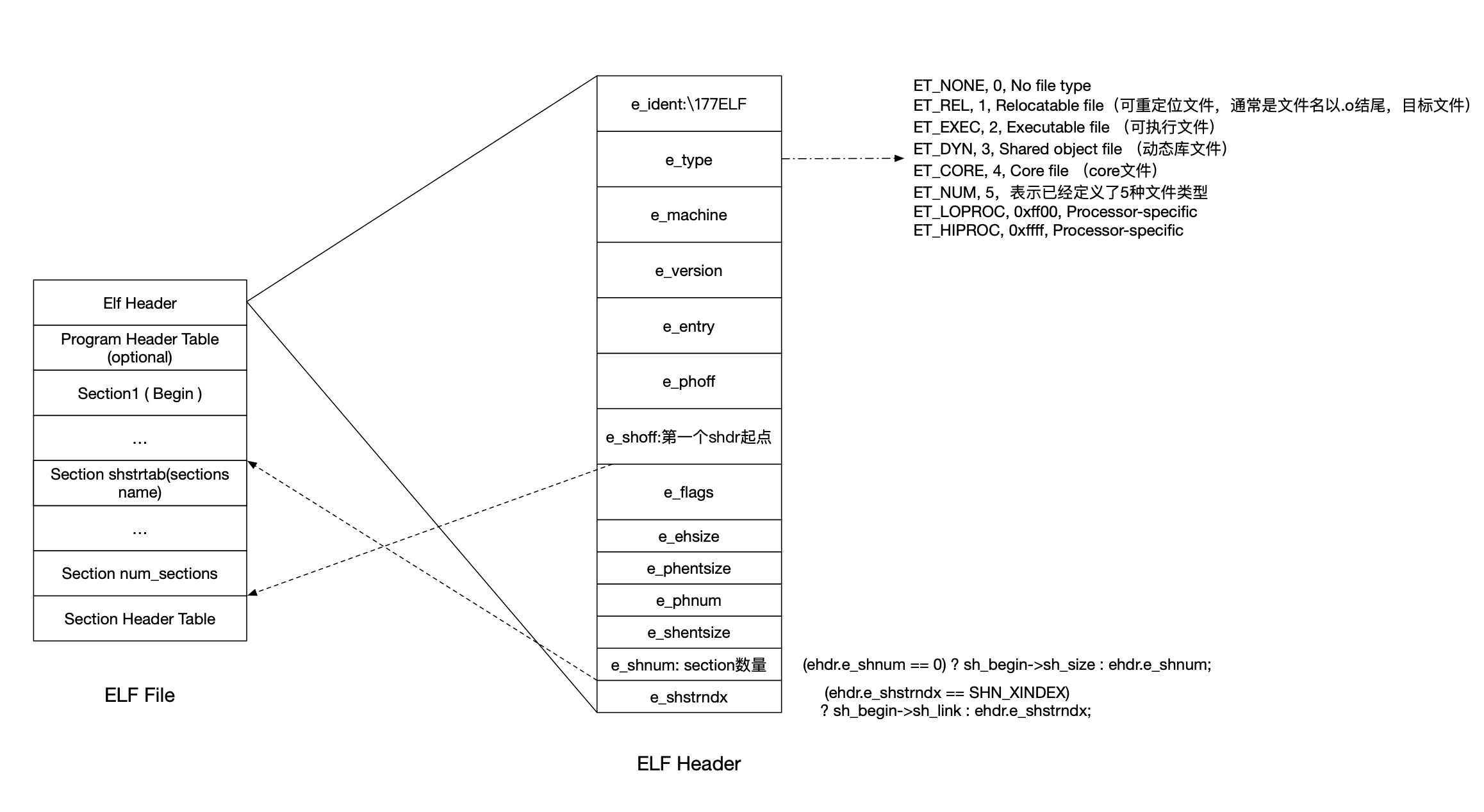
// e_shnum contains the total number of sections in an object file. // Since it is a 16-bit integer field, it's not large enough to // represent >65535 sections. If an object file contains more than 65535 // sections, the actual number is stored to sh_size field. i64 num_sections = (ehdr.e_shnum == 0) ? sh_begin->sh_size : ehdr.e_shnum;
// e_shstrndx is a 16-bit field. If .shstrtab's section index is // too large, the actual number is stored to sh_link field. i64 shstrtab_idx = (ehdr.e_shstrndx == SHN_XINDEX) ? sh_begin->sh_link : ehdr.e_shstrndx;
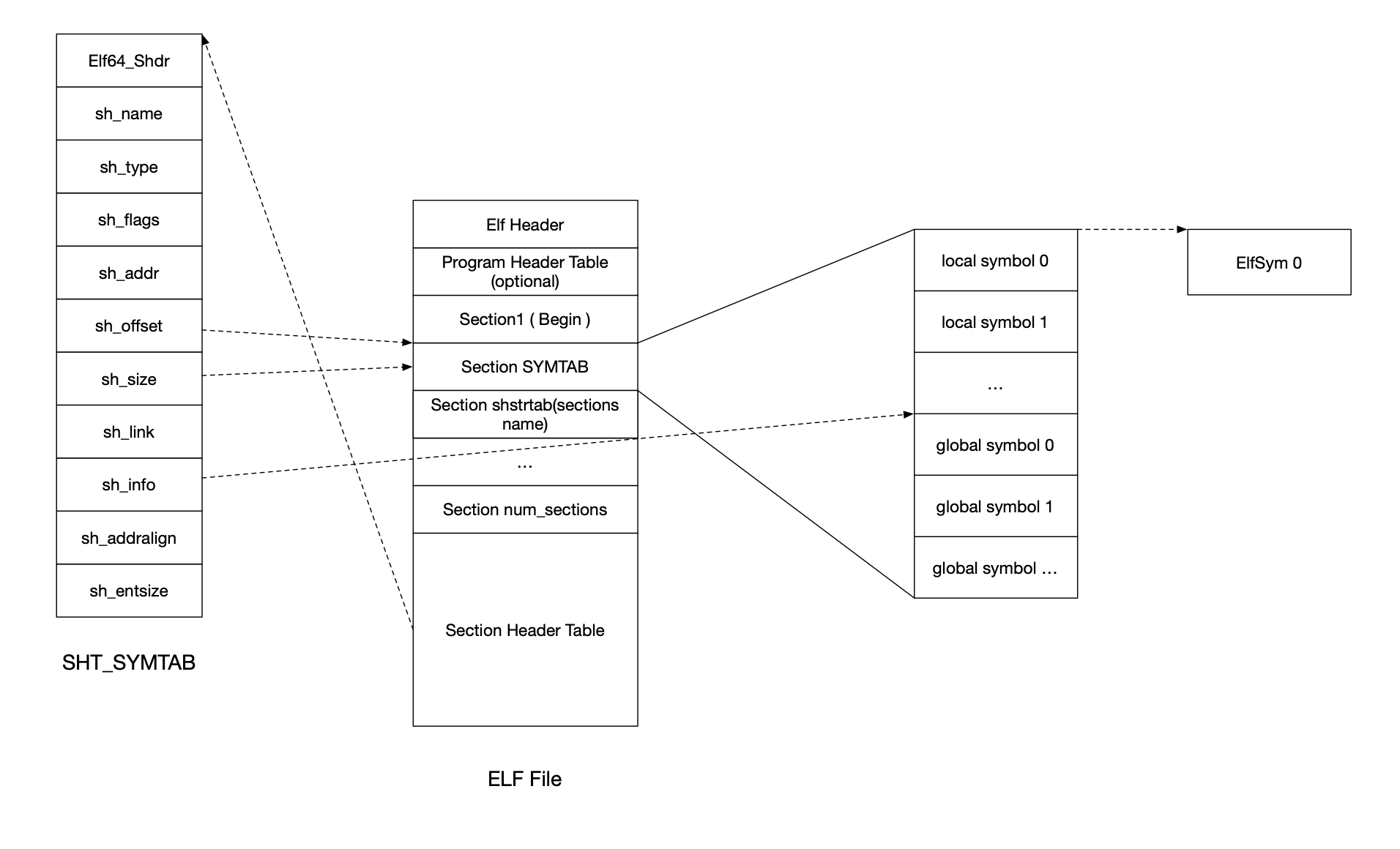
if (symtab_sec) { // In ELF, all local symbols precede global symbols in the symbol table. // sh_info has an index of the first global symbol. this->first_global = symtab_sec->sh_info; this->elf_syms = this->template get_data<ElfSym<E>>(ctx, *symtab_sec); this->symbol_strtab = this->get_string(ctx, symtab_sec->sh_link); }
SHF_EXCLUDE:This section is excluded from input to the link-edit of an executable or shared object. This flag is ignored if the SHF_ALLOC flag is also set, or if relocations exist against the section.
This section defines a section group. A section group is a set of sections that are related and that must be treated specially by the linker (see below for further details). Sections of type SHT_GROUP may appear only in relocatable objects (objects with the ELF header e_type member set to ET_REL). The section header table entry for a group section must appear in the section header table before the entries for any of the sections that are members of the group.
// Get the signature of this section group. if (shdr.sh_info >= this->elf_syms.size()) Fatal(ctx) << *this << ": invalid symbol index"; const ElfSym<E> &esym = this->elf_syms[shdr.sh_info];
This is a COMDAT group. It may duplicate another COMDAT group in another object file, where duplication is defined as having the same group signature. In such cases, only one of the duplicate groups may be retained by the linker, and the members of the remaining groups must be discarded.
for (i64 i = 1; i < this->first_global; i++) { const ElfSym<E> &esym = this->elf_syms[i]; if (esym.is_common()) Fatal(ctx) << *this << ": common local symbol?";
std::string_view name; if (esym.st_type == STT_SECTION) name = this->shstrtab.data() + this->elf_sections[get_shndx(esym)].sh_name; else name = this->symbol_strtab.data() + esym.st_name;
SHN_ABS This value specifies absolute values for the corresponding reference. For example, symbols defined relative to section number SHN_ABS have absolute values and are not affected by relocation.
// A symbol usually belongs to an input section, but it can belong // to a section fragment, an output section or nothing // (i.e. absolute symbol). `origin` holds one of them. We use the // least significant two bits to distinguish type. enum :uintptr_t { TAG_ABS = 0b00, TAG_ISEC = 0b01, TAG_OSEC = 0b10, TAG_FRAG = 0b11, TAG_MASK = 0b11, };
// Initialize global symbols for (i64 i = this->first_global; i < this->elf_syms.size(); i++) { const ElfSym<E> &esym = this->elf_syms[i];
// Get a symbol name std::string_view key = this->symbol_strtab.data() + esym.st_name; std::string_view name = key;
// Parse symbol version after atsign if (i64 pos = name.find('@'); pos != name.npos) { std::string_view ver = name.substr(pos + 1); name = name.substr(0, pos);
if (!ver.empty() && ver != "@") { if (ver.starts_with('@')) key = name; if (!esym.is_undef()) symvers[i - this->first_global] = ver.data(); } }
// Returns a symbol object for a given key. This function handles // the -wrap option. template <typename E> static Symbol<E> *insert_symbol(Context<E> &ctx, const ElfSym<E> &esym, std::string_view key, std::string_view name){ if (esym.is_undef() && name.starts_with("__real_") && ctx.arg.wrap.contains(name.substr(7))) { returnget_symbol(ctx, key.substr(7), name.substr(7)); }
// If we haven't seen the same `key` before, create a new instance // of Symbol and returns it. Otherwise, returns the previously- // instantiated object. `key` is usually the same as `name`. template <typename E> Symbol<E> *get_symbol(Context<E> &ctx, std::string_view key, std::string_view name){ typenamedecltype(ctx.symbol_map)::const_accessor acc; ctx.symbol_map.insert(acc, {key, Symbol<E>(name)}); returnconst_cast<Symbol<E> *>(&acc->second); }
最后提一下-wrap option选项
这个-wrap是在main中read_input_files之前的地方设置的
1 2 3
// Handle --wrap options if any. for (std::string_view name : ctx.arg.wrap) get_symbol(ctx, name)->wrap = true;
-wrap=symbol Use a wrapper function for symbol. Any undefined reference to symbol will be resolved to “__wrap_symbol”. Any undefined reference to “__real_symbol” will be resolved to symbol. … If you link other code with this file using –wrap malloc, then all calls to “malloc” will call the function “__wrap_malloc” instead. The call to “__real_malloc” in “__wrap_malloc” will call the real “malloc” function.
… Any undefined reference to symbol will be resolved to “__wrap_symbol”. Any undefined reference to “__real_symbol” will be resolved to symbol.
// Relocations are usually sorted by r_offset in relocation tables, // but for some reason only RISC-V does not follow that convention. // We expect them to be sorted, so sort them if necessary. template <typename E> void ObjectFile<E>::sort_relocations(Context<E> &ctx) { ifconstexpr(is_riscv<E>){ auto less = [&](const ElfRel<E> &a, const ElfRel<E> &b) { return a.r_offset < b.r_offset; };
for (i64 i = 1; i < sections.size(); i++) { std::unique_ptr<InputSection<E>> &isec = sections[i]; if (!isec || !isec->is_alive || !(isec->shdr().sh_flags & SHF_ALLOC)) continue;
 上一期主要讲了链接前的一些准备流程以及在mold中链接过程的简单介绍。这期开始我们从链接过程中的功能开始介绍。在开始之前,提前说明一下里面各种缩写有很多,我会在第一次出现时提及缩写具体含义是什么,如果后期更的期数比较多会考虑专门写一页缩写的参考,方便查阅。
上一期主要讲了链接前的一些准备流程以及在mold中链接过程的简单介绍。这期开始我们从链接过程中的功能开始介绍。在开始之前,提前说明一下里面各种缩写有很多,我会在第一次出现时提及缩写具体含义是什么,如果后期更的期数比较多会考虑专门写一页缩写的参考,方便查阅。