pixiv:70054356
这期的内容主要是讲完读取输入的部分,有一些之前遗漏的信息,以及之前未讲完的初始化ehframe以及shared object读取的部分。有许多地方默认读者读过上期内容,建议先阅读上期内容后再来查看本期。
https://homura.live/2023/02/26/mold/mold-1-read-input-files/
ObjectFile get_string 之前在读取符号表的时候是通过这种方式读取的,但我们没有讲解这个读取的细节
1 this ->symbol_strtab = this ->get_string (ctx, symtab_sec->sh_link);
elf/mold.h
1 2 3 4 5 6 7 8 template <typename E>inline std::string_view InputFile<E>::get_string (Context<E> &ctx, i64 idx) { assert (idx < elf_sections.size ()); if (elf_sections.size () <= idx) Fatal (ctx) << *this << ": invalid section index: " << idx; return this ->get_string (ctx, elf_sections[idx]); }
1 2 3 4 5 6 7 8 9 template <typename E>inline std::string_viewInputFile<E>::get_string (Context<E> &ctx, const ElfShdr<E> &shdr) { u8 *begin = mf->data + shdr.sh_offset; u8 *end = begin + shdr.sh_size; if (mf->data + mf->size < end) Fatal (ctx) << *this << ": section header is out of range: " << shdr.sh_offset; return {(char *)begin, (size_t )(end - begin)}; }
实际上是找到文件中对应offset的data作为开始,根据长度构造一个string_view ,注意这里并不是实际构造了一个string,因此返回的string并没有这块空间的所有权。
由get_string衍生出来的方法还有get_data,之前在读取elfsyms的时候就是使用了get_data
1 this ->elf_syms = this ->template get_data<ElfSym<E>>(ctx, *symtab_sec);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 template <typename E>template <typename T>inline std::span<T>InputFile<E>::get_data (Context<E> &ctx, const ElfShdr<E> &shdr) { std::string_view view = this ->get_string (ctx, shdr); if (view.size () % sizeof Fatal (ctx) << *this << ": corrupted section" ; return {(T *)view.data (), view.size () / sizeof } template <typename E>template <typename T>inline std::span<T> InputFile<E>::get_data (Context<E> &ctx, i64 idx) { if (elf_sections.size () <= idx) Fatal (ctx) << *this << ": invalid section index" ; return this ->template get_data<T>(elf_sections[idx]); }
这里直接获取了get_string的结果,并且将对应的结果映射为了一个对应数据的span
get_shndx 在之前从符号表取数据的时候是通过get_shndx实现的
elf/mold.h
1 2 3 4 5 6 7 8 9 template <typename E>inline i64 ObjectFile<E>::get_shndx (const ElfSym<E> &esym) { assert (&this ->elf_syms[0 ] <= &esym); assert (&esym <= &this ->elf_syms[this ->elf_syms.size () - 1 ]); if (esym.st_shndx == SHN_XINDEX) return symtab_shndx_sec[&esym - &this ->elf_syms[0 ]]; return esym.st_shndx; }
虽然符号中是有对应的shndx字段,但是这个字段的长度为16bit,如果超出这个长度的index那么需要去symtab_shndx_sec中获取。
这个限制在之前读取输入的时候多次遇到,比如说在构造InputFile类,读取shstrtab_idx的时候
input-files.cc
1 2 3 4 i64 shstrtab_idx = (ehdr.e_shstrndx == SHN_XINDEX) ? sh_begin->sh_link : ehdr.e_shstrndx;
eh_frame eh_frame段对于大多数人来说比较陌生,因此首先来讲解eh_frame是什么。eh_frame是包含了记录如何处理异常信息的段,当异常抛出的时候runtime会寻找一个eh_frame记录的信息并且来处理。
我们来看一下hello world的汇编
1 2 3 4 5 6 7 #include <stdio.h> int main () printf ("Hello world\n" ); return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 .section __TEXT,__text,regu lar,pure_instructions .build_version macos, 12 , 0 sdk_version 12 , 1 .globl _main ; -- Begin function main .p2align 2 _main: ; @main .cfi_startproc ; %bb.0 : sub sp, sp, #32 ; =32 stp x29, x30, [sp, #16 ] ; 16 -byte Folded Spill add x29, sp, #16 ; =16 .cfi_def_cfa w29, 16 .cfi_offset w30, -8 .cfi_offset w29, -16 mov w8, #0 str w8, [sp, #8 ] ; 4 -byte Folded Spill stur wzr, [x29, #-4 ] adrp x0, l_.str@PAGE add x0, x0, l_.str@PAGEOFF bl _printf ldr w0, [sp, #8 ] ; 4 -byte Folded Reload ldp x29, x30, [sp, #16 ] ; 16 -byte Folded Reload add sp, sp, #32 ; =32 ret .cfi_endproc ; -- End function .section __TEXT,__cstring,cstring_literals l_.str: ; @.str .asciz "Hello world\n" .subsections_via_symbols
关于eh_frame我有一个疑问,是否能像符号一样被strip掉?手动strip以后发现elf大小并没有发生改变。关于这个问题stackoverflow有这样一条回答
Why GCC compiled C program needs .eh_frame section?
You can disable generation of .eh_frame with -fno-asynchronous-unwind-tables for individual translation units, and this mostly eliminates the size cost
You cannot strip them with the strip command later; since .eh_frame is a section that lives in the loaded part of the program (this is the whole point), stripping it modifies the binary in ways that break it at runtime.
大意是不能通过strip消除,但是eh_frame在gcc中可以通过开启特殊的编译选项避免生成。
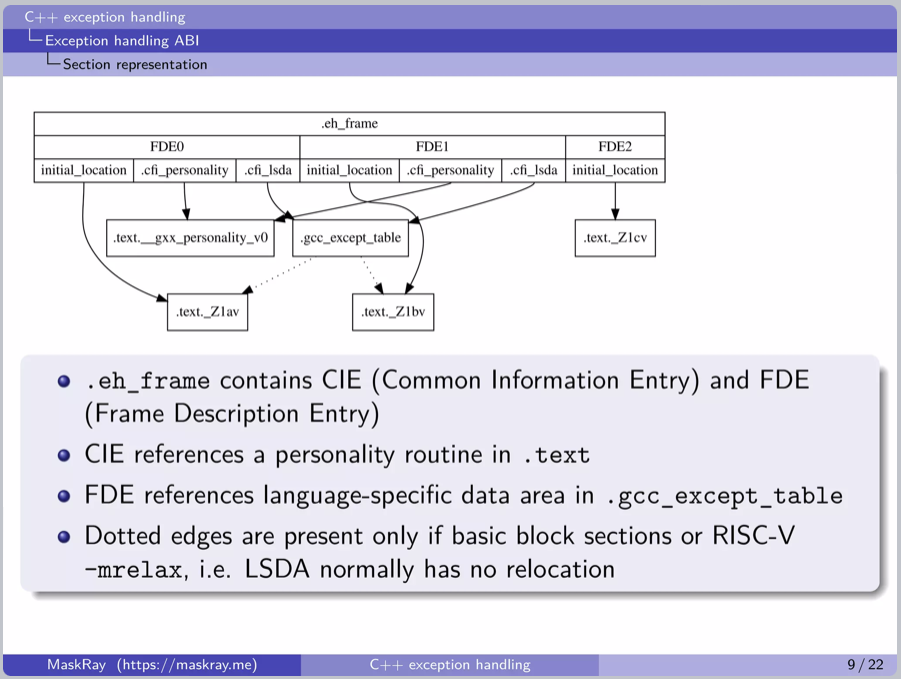
eh_frame的结构 Exception Frames
这里不详细介绍里面的具体字段了。简单来说,每个eh_frame段中会包含至少一个CFI(Call Frame Information),而每个CFI包含一个CIE(Common Information Entry),之后紧接着跟着许多FDE(Frame Description Entry)
一个CFI对应了一个单一的object文件,如果是多个object文件合并那么就会有多个,因此至少存在一个。CFI中包含了一个CIE,也就是这个object里的common information,而后面跟随的许多FDE则是对应了各个function。
这里引用一下MaskRay聚聚的资料,里面包含了更具体严谨的描述。
initialize_ehframe_sections 对于链接器来说,ehframe和其他段不同是单独进行parse的。注释中给出了以下几条原因
避免大量dead section的字段。如果只是最后拷贝所有的eh_frame则会有许多针对dead section的字段。
减少section的大小。删除function的时候顺便删除FDE,所以eh_frame不包含dead FDE。
增加搜索效率。扫描eh_frame段查找一个record是一个O(n)操作,通过linker创建一个sorted list后可以通过二分查找降低复杂度到O(log n)。
接下来我们看一下具体的实现
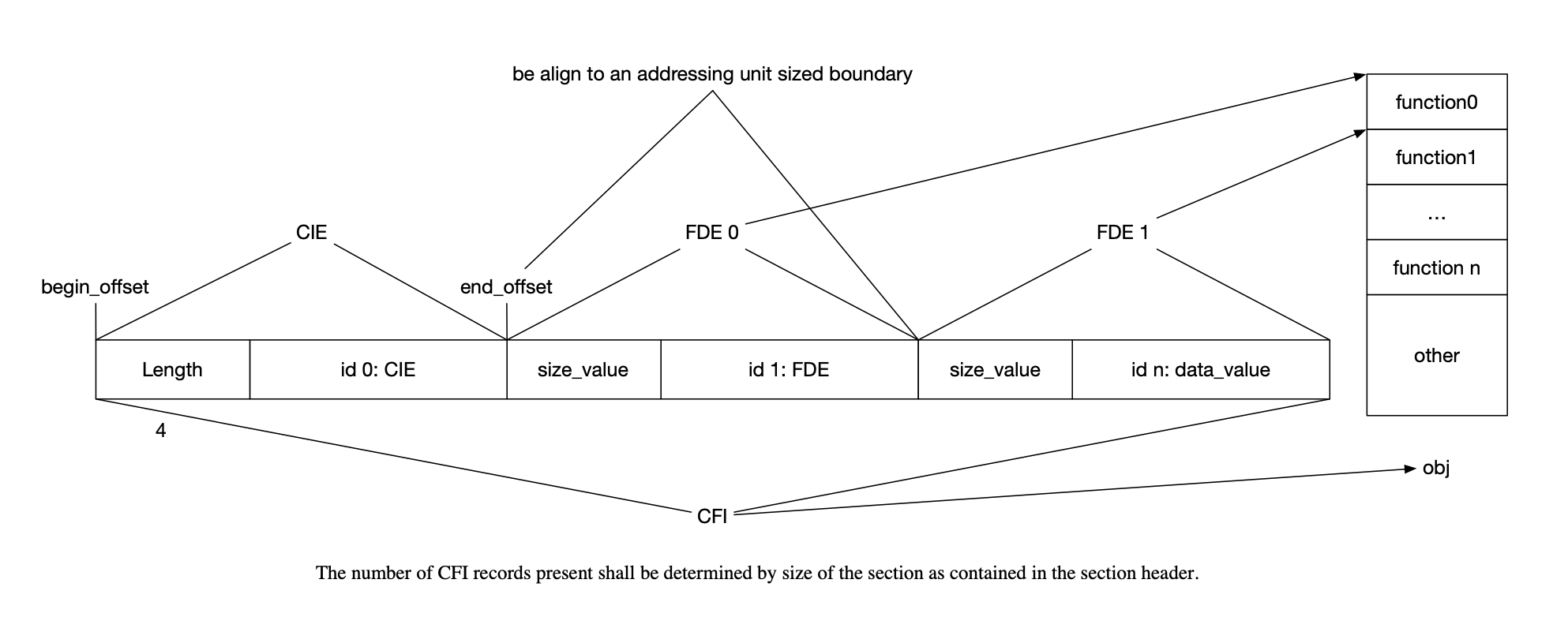
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 template <typename E>void ObjectFile<E>::read_ehframe (Context<E> &ctx, InputSection<E> &isec) { std::span<ElfRel<E>> rels = isec.get_rels (ctx); i64 cies_begin = cies.size (); i64 fdes_begin = fdes.size (); std::string_view contents = this ->get_string (ctx, isec.shdr ()); i64 rel_idx = 0 ; for (std::string_view data = contents; !data.empty ();) { i64 size = *(U32<E> *)data.data (); if (size == 0 ) break ; i64 begin_offset = data.data () - contents.data (); i64 end_offset = begin_offset + size + 4 ; i64 id = *(U32<E> *)(data.data () + 4 ); data = data.substr (size + 4 ); i64 rel_begin = rel_idx; while (rel_idx < rels.size () && rels[rel_idx].r_offset < end_offset) rel_idx++; assert (rel_idx == rels.size () || begin_offset <= rels[rel_begin].r_offset); if (id == 0 ) { cies.emplace_back (ctx, *this , isec, begin_offset, rels, rel_begin); } else { if (rel_begin == rel_idx || rels[rel_begin].r_sym == 0 ) { continue ; } if (rels[rel_begin].r_offset - begin_offset != 8 ) Fatal (ctx) << isec << ": FDE's first relocation should have offset 8" ; fdes.emplace_back (begin_offset, rel_begin); } }
根据这个解析过程以及参考格式描述我们能够画出这样一张图
在读取完所有基本的段以后,将CIE关联到FDE中
1 2 3 4 5 6 7 8 9 10 11 auto find_cie = [&](i64 offset) { for (i64 i = cies_begin; i < cies.size (); i++) if (cies[i].input_offset == offset) return i; Fatal (ctx) << isec << ": bad FDE pointer" ; }; for (i64 i = fdes_begin; i < fdes.size (); i++) { i64 cie_offset = *(I32<E> *)(contents.data () + fdes[i].input_offset + 4 ); fdes[i].cie_idx = find_cie (fdes[i].input_offset + 4 - cie_offset); }
最后将FDE关联到InputSection中。注意这里进行了stable_sort,上面提到的第三条增加搜索效率就是通过这里实现的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 std::stable_sort (fdes.begin () + fdes_begin, fdes.end (), [&](const FdeRecord<E> &a, const FdeRecord<E> &b) { return get_isec (a)->get_priority () < get_isec (b)->get_priority (); }); for (i64 i = fdes_begin; i < fdes.size ();) { InputSection<E> *isec = get_isec (fdes[i]); assert (isec->fde_begin == -1 ); isec->fde_begin = i++; while (i < fdes.size () && isec == get_isec (fdes[i])) i++; isec->fde_end = i; }
至此,整个eh_frame部分的初始化就完毕了。
SharedFile create 首先我们来看一下SharedFile的构造
1 2 3 4 5 6 7 8 9 10 11 12 13 14 template <typename E>SharedFile<E> * SharedFile<E>::create (Context<E> &ctx, MappedFile<Context<E>> *mf) { SharedFile<E> *obj = new SharedFile (ctx, mf); ctx.dso_pool.emplace_back (obj); return obj; } template <typename E>SharedFile<E>::SharedFile (Context<E> &ctx, MappedFile<Context<E>> *mf) : InputFile<E>(ctx, mf) { this ->is_needed = ctx.as_needed; this ->is_alive = !ctx.as_needed; }
这部分没什么特别要讲的,关于is_needed和is_alive会涉及到关于whole-archive这个选项,之后会再单独开文章讲解。构造基类InputFile之前在ObjectFile的部分已经讲过了,不再赘述。接着来看parse的部分。
parse 首先是找到DYNSYM段
1 2 3 4 5 template <typename E>void SharedFile<E>::parse (Context<E> &ctx) { symtab_sec = this ->find_section (SHT_DYNSYM); if (!symtab_sec) return ;
之后读取符号表和ver信息,这些是Shared only的成员。而soname是针对一个dso的,所以个dso关联一个soname
1 2 3 this ->symbol_strtab = this ->get_string (ctx, symtab_sec->sh_link);soname = get_soname (ctx); version_strings = read_verdef (ctx);
读取具体的符号信息以及符号版本信息
1 2 3 4 5 6 std::span<ElfSym<E>> esyms = this ->template get_data<ElfSym<E>>(ctx, *symtab_sec); std::span<U16<E>> vers; if (ElfShdr<E> *sec = this ->find_section (SHT_GNU_VERSYM)) vers = this ->template get_data<U16<E>>(ctx, *sec);
对于DYNSYM来说symtab_sec->sh_info是开始的符号数量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 for (i64 i = symtab_sec->sh_info; i < esyms.size (); i++) { u16 ver; if (vers.empty () || esyms[i].is_undef ()) ver = VER_NDX_GLOBAL; else ver = (vers[i] & ~VERSYM_HIDDEN); if (ver == VER_NDX_LOCAL) continue ; std::string_view name = this ->symbol_strtab.data () + esyms[i].st_name; bool is_hidden = (!vers.empty () && (vers[i] & VERSYM_HIDDEN)); this ->elf_syms2.push_back (esyms[i]); this ->versyms.push_back (ver); if (is_hidden) { std::string_view mangled_name = save_string ( ctx, std::string (name) + "@" + std::string (version_strings[ver])); this ->symbols.push_back (get_symbol (ctx, mangled_name, name)); } else { this ->symbols.push_back (get_symbol (ctx, name)); } }
这个for循环中针对每个符号信息来说做了以下几件事情
处理version信息。
跳过只有一个VER_NDX_LOCAL属性的
vers为空或esym未定义,则是global的(大概用于symbol resolve去寻找定义。因此设为了GLOBAL
不为空且有定义,那么就不是HIDDEN的
1 2 3 static constexpr u32 VER_NDX_LOCAL = 0 ;static constexpr u32 VER_NDX_GLOBAL = 1 ;static constexpr u32 VERSYM_HIDDEN = 0x8000 ;
添加elf_syms2(Shared Only的字段)以及versysms
处理hidden的符号,hidden的话要mangled才行
设置基本信息后结束
1 2 3 4 this ->elf_syms = elf_syms2;this ->first_global = 0 ;static Counter counter ("dso_syms" ) counter += this ->elf_syms.size ();
这里first_global设置为0,也就是说dso中所有的符号都是global的。
get_soname 1 2 3 4 5 6 7 8 9 10 11 12 template <typename E>std::string SharedFile<E>::get_soname (Context<E> &ctx) { if (ElfShdr<E> *sec = this ->find_section (SHT_DYNAMIC)) for (ElfDyn<E> &dyn : this ->template get_data<ElfDyn<E>>(ctx, *sec)) if (dyn.d_tag == DT_SONAME) return this ->symbol_strtab.data () + dyn.d_val; if (this ->mf->given_fullpath) return this ->filename; return filepath (this ->filename).filename ().string (); }
找到DYNAMIC段,从里面的ElfDyn中查找tag为DT_SONAME的,找不到就用依靠完整文件路径作为soname。
关于ElfDyn
1 2 3 4 5 6 template <> struct ElfDyn <struct EL64Dyn { ul64 d_tag; ul64 d_val; };
在elf规范中关于DT_SONAME这个tag的信息
Name
d_un
Executable
Shared Object
DT_SONAME
d_val
ignored
optional
This element holds the string table offset of a null-terminated string, giving the name of the shared object. The offset is an index into the table recorded in the DT_STRTAB entry. See “Shared Object Dependencies” below for more information about these names.
verdef
Symbol versioning is a GNU extension to the ELF file format.
Versions are just strings, and no ordering is defined between them. For example, “GLIBC_2.15” is not considered a newer version of “GLIBC_2.2.5” or vice versa. They are considered just different.
If a shared object file has versioned symbols, it contains a parallel array for the symbol table. Version strings can be found in that parallel table.
One version is considered the “default” version for each shared object. If an undefiend symbol foo is resolved to a symbol defined by the shared object, it’s marked so that it’ll be resolved to (foo, the default version of the library) at load-time.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 template <typename E>std::vector<std::string_view> SharedFile<E>::read_verdef (Context<E> &ctx) { std::vector<std::string_view> ret (VER_NDX_LAST_RESERVED + 1 ) ; ElfShdr<E> *verdef_sec = this ->find_section (SHT_GNU_VERDEF); if (!verdef_sec) return ret; std::string_view verdef = this ->get_string (ctx, *verdef_sec); std::string_view strtab = this ->get_string (ctx, verdef_sec->sh_link); ElfVerdef<E> *ver = (ElfVerdef<E> *)verdef.data (); for (;;) { if (ret.size () <= ver->vd_ndx) ret.resize (ver->vd_ndx + 1 ); ElfVerdaux<E> *aux = (ElfVerdaux<E> *)((u8 *)ver + ver->vd_aux); ret[ver->vd_ndx] = strtab.data () + aux->vda_name; if (!ver->vd_next) break ; ver = (ElfVerdef<E> *)((u8 *)ver + ver->vd_next); } return ret; }
拿一个helloworld的elf看一下
1 2 3 4 readelf -S ./a.out [ 8 ] .gnu.version VERSYM 0000000000000516 00000516 000000000000000 e 0000000000000002 A 6 0 2
这里的全体大小为2,我们再看一下符号
1 2 3 4 nm ./a.out | grep "@" w __cxa_finalize@GLIBC_2.2 .5 U __libc_start_main@GLIBC_2.34 U puts@GLIBC_2.2 .5
其中两个是重复的符号,去重后也就是2个符号
对比ObjectFile和SharedFile 最后我们通过分析ObjectFile和SharedFile相关的异同来结束这期内容。
相比于ObjectFile的复杂解析过程,SharedFile的整个过程显得十分简单。这和文件本身的性质与使用场景都有关系。dso加载符号的定义以及其他信息绝大部分都是在运行时,因此在链接期间并不需要做太多操作,其主要用途是将会被引用的符号加入到决议过程,同时将对应符号的版本信息和dso的soname加入到生成的产物中,以便在运行时进行加载。在谷歌搜索的时候搜到了这样一句话,我觉得概括的更好
A DSO can be used in place of archive libraries and will minimize overall memory usage because code is shared.
在链接的时候dso的作用是in place of archive libraries,所以并不需要太多的信息。
虽然SharedFile在链接的时候并没有解析ObjectFile中许多信息,但是那些信息仍然是存在的,只是在链接的时候无需参与,而是全部交给运行时加载来处理。虽然在mold的类结构中ObjectFile和SharedFile都是直接继承自InputFile,但对于实际的object和dso来说我觉得dso更倾向于是特别的object,不过这个从dso的全名(dynamic shared object)也能看出来了。
我的博客即将同步至腾讯云开发者社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=239vtuizwri8w